Revolutionizing Information Retrieval: The Role of Large Language Models in a Post-Search Engine Era
LLMs will introduce a conversational approach to interacting with information, which disrupts the way we find and consume digital content.

Introduction
For more than 30 years, search engines have served as the go-to method for discovering information online.
Yet, with the exponential growth of the Internet and the vast expansion of accessible data, search engines have been facing challenges in delivering their ability to retrieve the most relevant and useful information for users.
Due to this, there has been an escalating curiosity surrounding the prospects of Large Language Models (LLMs) as potential game-changers, capable of revolutionsing information retrieval and analysis.
While search engines will not disappear entirely, they are likely to transition into “ranking” engines that work in tandem with LLMs to rank content, data, and information in regards to the context the user is exploring. Additionally, LLMs will introduce a conversational approach to interacting with information, which radically transforms the user experience when it comes to finding and consuming digital content.
Background
Before starting, let’s spend a few introductory words about Large Language Models (LLMs).
LLMs represent a category of Artificial Intelligence models that employ deep learning algorithms to comprehend and produce language that closely resembles human language. Their capabilities span a broad spectrum of activities, encompassing question-answering, text summarization, response generation, language translation, and various other functions. These models possess the capacity to grasp the intricacies and contextual subtleties of language, extract and synthesise data from diverse origins, and acquire new proficiencies and domains by building upon their existing repository of trained data.
In recent months, diverse emerging models with varying degrees of efficiency and output quality have surfaced; nonetheless, in general, the results yielded by these models are astounding and possess the potential to revolutionise numerous industries.
Information Retrieval Beyond Search Engines
Traditional search engines, as we know them today, are primarily designed to process explicit queries or keywords and retrieve relevant information based on those queries. They rely on algorithms and ranking mechanisms to analyse web pages, index their content, and determine their relevance to specific search queries.
Search engines aim to provide users with a list of ranked results that best match their queries, often using factors such as keyword relevance, page authority, and user engagement metrics to determine the ranking.
However, with the advent of Large Language Models (LLMs) and their ability to comprehend natural language queries and generate personalised responses, there is a growing recognition of the limitations of traditional search engines. LLMs can synthesize long textual data that makes sense to the reader and remains relevant to their original query. This is achieved through their pre-training on vast amounts of data, contextual understanding, transfer learning, a large parameter space, and training on human-generated data. LLMs provide more accurate and tailored results which can be further explored by engaging in an actual conversation with the model.
Given this development, search engines may soon find themselves relinquishing their long held position as gatekeepers and “front pages” of the Web. This change could lead to the emergence of ranking engines, designed to work in tandem with Large Language Models.
The essential role of a ranking engine would be to find and present the most relevant information from the Internet to the LLM, based on the specific needs and preferences interpreted by the LLM. In this way, search engines will no longer show information to the user directly, but rather send it to the Language Model for further synthesis.
Once the relevant information has been ranked and synthesised by the model by tapping into their knowledge base, it can be sent back to the user in the form of a response to their original query.
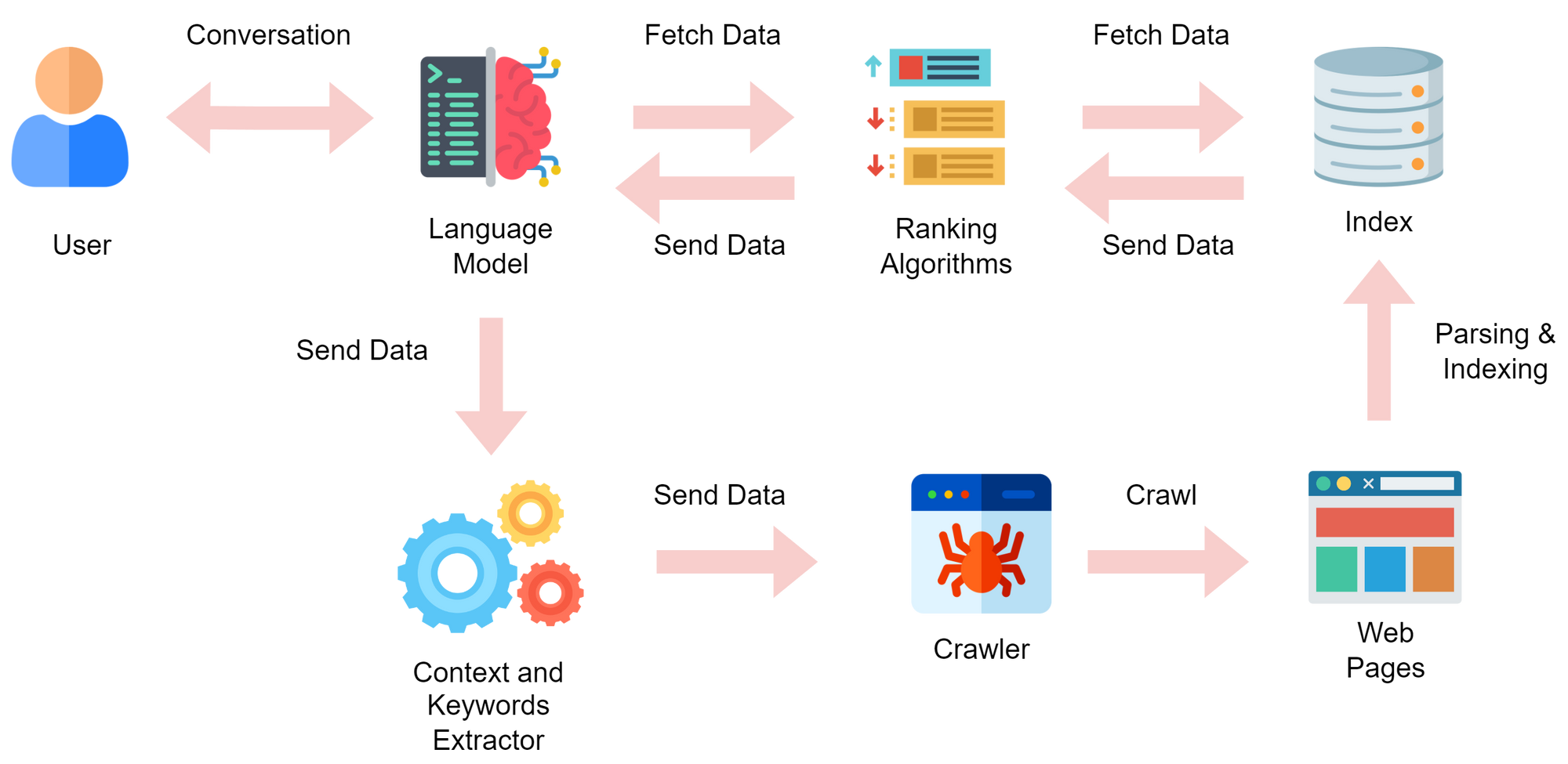
This transition acknowledges the power and potential of LLMs in understanding natural language and generating personalised responses, while also recognizing that ranking engines are essential for organising and filtering information effectively. By combining the strengths of LLMs and ranking engines, the goal is to deliver highly relevant and personalised results that align with the user’s intent, context, and preferences in a way that could be digested easier than ever.
This transition from search engines to ranking engines acting in the back-end of Language Models would show a shift from a singular focus on information retrieval to a broader emphasis on information retrieval, synthesis and visualisation.
LLMs would provide the capabilities for understanding and generating language, while ranking engines would select and retrieve information for the LLMs so that it can be presented to the user in an easy way.
Advantages of LLMs over Search Engines as the front page of the Web
A fundamental benefit of LLMs over search engines lies in their capacity to comprehend intricate queries and produce personalised responses. Unlike search engines, which depend on explicit queries or keywords for information retrieval, LLMs possess the capability to grasp and interpret natural language queries, resulting in more precise and pertinent replies. LLMs can also tailor their responses based on user preferences and prior interactions, enhancing the usefulness and relevance of the information provided.
Another advantage offered by LLMs is related to their capacity to learn and adapt to novel tasks and domains through their existing knowledge. Search engines are confined by fixed algorithms and data structures, which can restrict their flexibility and adaptability. Conversely, LLMs possess the ability to assimilate new data and user interactions, enabling them to enhance their accuracy and relevance progressively as time unfolds.
Thanks to their capability to extract relevant chunks of information from documents, LLMs utility can potentially expand beyond web-based content. By efficiently parsing and analysing vast volumes of textual data, LLMs can extract key insights, summarise complex documents, and provide concise and pertinent information to users. This ability to leverage and distil information from various document sources (e.g. PDFs, .csv and so on), extends their utility beyond simple knowledge extraction becoming actual productivity engines.
To further elevate the discussion on versatility, it is worth highlighting the immense potential of integrating LLMs with diverse software systems. This can potentially empower users to interact with their software suite in a conversational way in order to effortlessly execute specific tasks. This integration paves the way for a truly conversational and streamlined user experience, offering the advantage of automating numerous tasks, including creating and polishing textual data, arranging appointments, or performing in-depth data analysis. This automation capability can significantly save time and resources for both individuals and organisations, optimising their workflows and enhancing overall productivity.
Ultimately, LLMs possess the ability to cater to a diverse range of languages, opening numerous possibilities in terms of accessibility of content and information for a global audience. Users can engage with LLMs in their preferred language, even if the underlying information the model has been trained on was not initially available in that specific language. This inclusive attribute aids in dismantling language barriers and can greatly improve information accessibility for individuals who speak different languages. No matter the language webpages are written in, the Language Model can analyse them and automatically present results in the language selected by the user.
Challenges and Limitations of Large Language Models
While LLMs hold significant promise, they are not without their fair share of challenges and limitations. Foremost among these is the accuracy and validity of the information they present. LLMs generate responses based on their training data, which may occasionally lack accuracy, currency and may be affected by bias. Consequently, there is a risk of users being exposed to erroneous or incomplete information.
Privacy concerns represent another significant challenge tied to LLMs. The data employed for training LLMs could potentially include personal or sensitive information, thereby engendering apprehensions regarding data privacy and security. Furthermore, the data generated during interactions between LLMs and users may also give rise to privacy concerns. Safeguarding user privacy and ensuring secure handling of data emerge as vital considerations within the context of LLM utilisation.

Lastly, LLMs lack the ability to automatically evolve alongside published content and require continuous training and updates to stay current. This process can be laborious and resource-intensive for both individuals and organisations.
It is worth noting that emerging techniques such as Low-Rank Adaptation of Large (LoRA) Language Models are being developed exactly with the aim to improve the efficiency for model training and model fine-tuning, which offers potential avenues for streamlining the updating process and mitigating associated challenges.
Closing Thoughts
LLMs offer the remarkable potential to extract content and information and reconstruct it in a manner that can be tailored to the unique needs of each user. Irrespective of factors such as time availability, attention span, language barriers, and other constraints, LLMs can curate and present information in a highly personalised and user-centric way. This ability, when coupled with the search engines functions of crawling and ranking information from the Internet, has the potential to alleviate the pain points and enhance the overall user experience when it comes to navigating web and digital content.
However, it is essential to acknowledge and address the challenges and limitations that accompany LLMs. Ensuring the accuracy and validity of information presented, safeguarding privacy, and maintaining up-to-date training and updates are critical areas that require continuous attention and improvement.
As LLMs continue to evolve and overcome these challenges, their capacity to adapt and optimise information delivery to individual users’ preferences and constraints is poised to reshape the way we interact with and consume information.
In the scenario depicted, search engines are not expected to disappear entirely but rather transition into ranking engines that work alongside LLMs for information retrieval and analysis. This combined approach, where LLMs are supported by ranking engines, presents a promising future where users can converse with information and benefit from highly personalised and context-aware responses.
Thanks to the conversational capabilities of Language Models, users would also be able to ‘conversate’ with the content that has been retrieved, asking questions, exploring related topics, or even requesting summarisations of complex information.
This interactive dimension adds a layer of personalization and adaptability that surpasses the capabilities of traditional search engines. Additionally, it can potentially empower users to delve deeper into the subject matter, fostering a more engaged and enriched learning experience. This unique blend of intelligent information retrieval and interactive exploration has the potential to redefine the way we interact with and consume digital information.
Attributions
Icons from Freepik, Becris, Dinosoft Labs, Design Circle and Smash Icons